Fast Whitening Transformation
Developed by Gabriel Hoffman
Run on 2025-07-09 13:14:39.025354
Source:vignettes/decorrelate.Rmd
decorrelate.RmdData whitening is a widely used preprocessing step to remove correlation structure since statistical models often assume independence (Kessy, et al. 2018). The typical procedures transforms the observed data by an inverse square root of the sample correlation matrix (Figure 1). For low dimension data (i.e. n > p), this transformation produces transformed data with an identity sample covariance matrix. This procedure assumes either that the true covariance matrix is know, or is well estimated by the sample covariance matrix. Yet the use of the sample covariance matrix for this transformation can be problematic since 1) the complexity is \mathcal{O}(p^3) and 2) it is not applicable to the high dimensional (i.e. n \ll p) case since the sample covariance matrix is no longer full rank.
Here we use a probabilistic model of the observed data to apply a whitening transformation. Our Gaussian Inverse Wishart Empirical Bayes (GIW-EB) 1) model substantially reduces computational complexity, and 2) regularizes the eigen-values of the sample covariance matrix to improve out-of-sample performance.
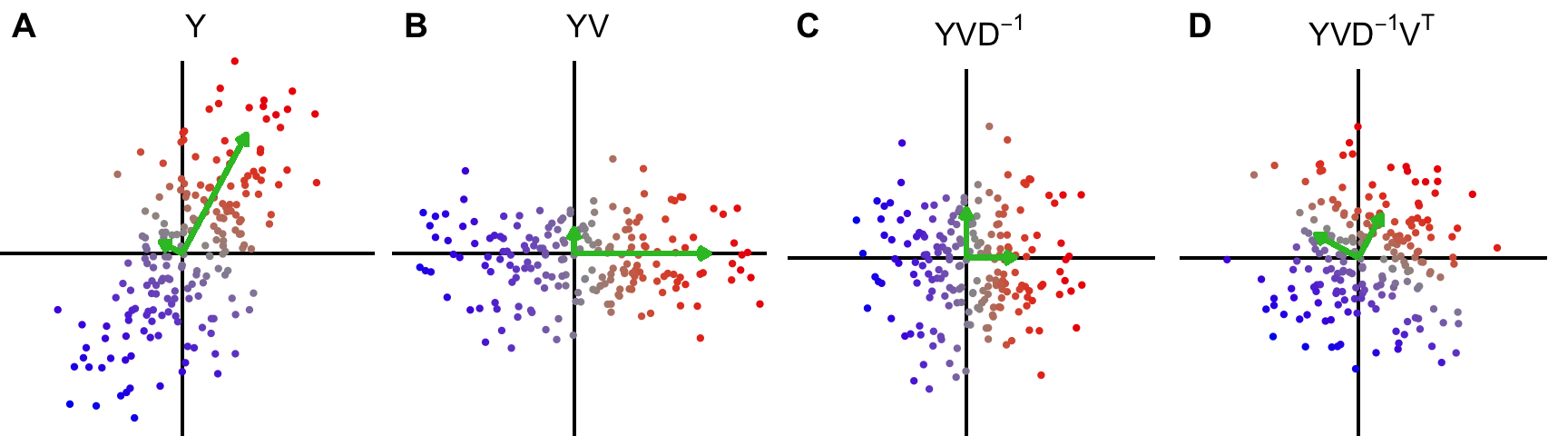
Figure 1: Intuition for data whitening transformation. Given the singular value decomposition of Y/\sqrt{n} after centering columns is UDV^T, the steps in the transformation are: A) Original data, B) Data rotated along principal components, C) Data rotated and scaled, D) Data rotated, scaled and rotated back to original axes. Green arrows indicate principal axes and lengths indicate eigen-values.
Basic usage
library(decorrelate)
library(Rfast)
n <- 500 # number of samples
p <- 200 # number of features
# create correlation matrix
Sigma <- autocorr.mat(p, 0.9)
# draw data from correlation matrix Sigma
Y <- rmvnorm(n, rep(0, p), sigma = Sigma * 5.1, seed = 1)
rownames(Y) <- paste0("sample_", 1:n)
colnames(Y) <- paste0("gene_", 1:p)
# eclairs decomposition implements GIW-EB method: *E*stimate
# *c*ovariance/correlation with *l*ow *r*ank and *s*hrinkage
ecl <- eclairs(Y)
# decorrelate data using eclairs decomposition
Y_whitened <- decorrelate(Y, ecl)
# the same whitening can be performed with one command where the eigen-value
# shrinkage is performed internally
Y_whitened2 <- whiten(Y)Here plot A) the eigen-values of the covariance matrix before and after shrinkage. B) The correlation of the observed and C) whitened data.
par(mfrow = c(1, 3))
# plot shrinkage of eigen-values
plot(ecl)
# correlation between variables in observed data
image(cor(Y), axes = FALSE, main = "Correlation of observed data")
# decorrelate data using eclairs decomposition
image(cor(Y_whitened), axes = FALSE, main = "Correlation of whitened data")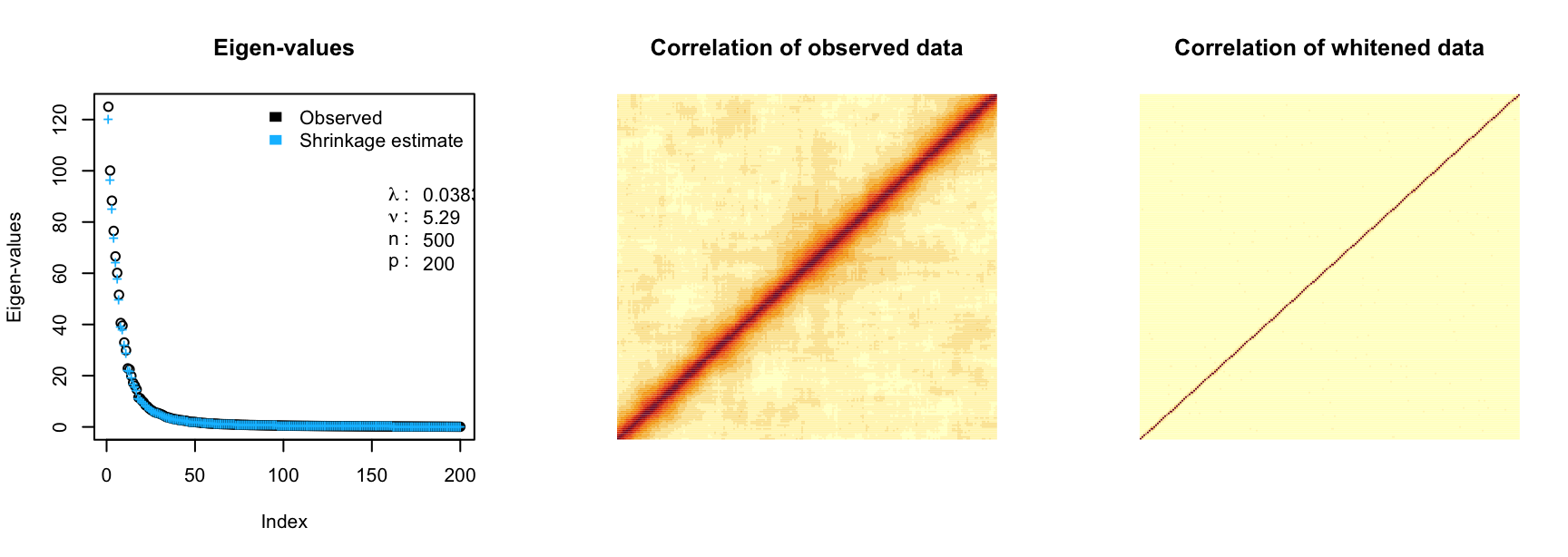
Advanced usage
The decorrelate package has advanced features to examine
details of the whitening transformation.
Directly compute whitening matrix
While eclairs(), decorrelate(), and
whiten() perform the probabilistic whitening transformation
efficiently without directly computing the whitening matrix,
getWhiteningMatrix() can directly compute the matrix.
# compute whitening matrix from eclairs decomposition
W <- getWhiteningMatrix(ecl)
# transform observed data using whitening matrix
Z <- tcrossprod(Y, W)
# evalute difference between whitened computed 2 ways
max(abs(Z - Y_whitened))## [1] 4.085621e-14The difference between function is due only to machine precision.
Explicit covariance or correlation
The full covariance for correlation matrix implied by the
eclairs() decomposition can be computed explicitly. Note
that computing and storing these matries is O(p^2), it may not feasable for large
datasets.
Sample from multivariate normal
The form of the eclairs() decomposition can be used to
efficiently sample from a multivariage normal distribution with
specified covariance.
# draw from multivariate normal
n <- 1000
mu <- rep(0, ncol(Y))
# using eclairs decomposition
X.draw1 <- rmvnorm_eclairs(n, mu, ecl)Low-rank models
A low rank eclairs() decomposition can be computed more
efficiently when k is small relative to
min(n,p). Importantly, the emprical
Bayes estimate of the shrinkage parameter \lambda can still be computed accurately for
sufficiently large k. Note that the low
rank method trades computational efficientcy for accuracy in the
whitening transform.
# use low rank decomposition with 50 components
ecl <- eclairs(Y, k = 60)
# decorrelate data using eclairs decomposition
Y_whitened <- decorrelate(Y, ecl)
In this case, the low rank whitening produces transformed features that are approximately independent. The approximation improves as the rank increases.
Computing condition number
Compute the condition number (i.e. the ratio between the largest and
smallest eigen-value) of the correlation/covariance matrix from the
eclairs() decomposition.
kappa(ecl)## [1] 658.3446Removing correlation vs covariance
By default eclairs() computes the covariance
between columns by using the default
compute = "covariance". Running decorrelate()
using this removes the covariance between columns. Setting
compute = "correlation", evaluates and then removes
correlation between columns while retaining the variance.
library(clusterGeneration)
# generate covariance matrix, where the diagonals (i.e. variances) vary
Sigma <- genPositiveDefMat(p, rangeVar = c(1, 1e+06))$Sigma
Y <- rmvnorm(n, rep(0, p), sigma = Sigma)
# examine variances of the first 5 variables
apply(Y, 2, var)[1:5]## [1] 5.082884 2.853566 1.083664 3.687911 1.491565
# transform removes covariance between columns so variance of transformed
# features are *approximately* equal
ecl_cov <- eclairs(Y, compute = "covariance")
Z1 <- decorrelate(Y, ecl_cov)
# variance are *approximately* equal
apply(Z1, 2, var)[1:5]## [1] 0.9830960 0.9939579 0.9924317 0.9939929 0.9945367
# transform removes **correlation** between columns but variables are not
# scaled
ecl_cor <- eclairs(Y, compute = "correlation")
Z2 <- decorrelate(Y, ecl_cor)
# variances are not standardized
apply(Z2, 2, var)[1:5]## [1] 5.012871 2.830468 1.066778 3.661699 1.476049Session Info
## R version 4.3.0 (2023-04-21)
## Platform: x86_64-apple-darwin22.4.0 (64-bit)
## Running under: macOS Ventura 13.5
##
## Matrix products: default
## BLAS: /Users/gabrielhoffman/prog/R-4.3.0/lib/libRblas.dylib
## LAPACK: /usr/local/Cellar/r/4.3.0_1/lib/R/lib/libRlapack.dylib; LAPACK version 3.11.0
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## time zone: America/New_York
## tzcode source: internal
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] clusterGeneration_1.3.7 MASS_7.3-60 latex2exp_0.9.6
## [4] colorRamps_2.3.1 cowplot_1.1.1 ggplot2_3.4.2
## [7] mvtnorm_1.2-2 decorrelate_0.0.18
##
## loaded via a namespace (and not attached):
## [1] generics_0.1.3 sass_0.4.6 utf8_1.2.3 stringi_1.7.12
## [5] lattice_0.21-8 digest_0.6.33 magrittr_2.0.3 evaluate_0.21
## [9] grid_4.3.0 fastmap_1.1.1 rprojroot_2.0.3 jsonlite_1.8.5
## [13] Matrix_1.5-4.1 formatR_1.14 purrr_1.0.1 fansi_1.0.4
## [17] scales_1.2.1 codetools_0.2-19 textshaping_0.3.6 jquerylib_0.1.4
## [21] Rdpack_2.4 cli_3.6.1 rlang_1.1.1 rbibutils_2.2.13
## [25] munsell_0.5.0 withr_2.5.0 CholWishart_1.1.2 cachem_1.0.8
## [29] yaml_2.3.7 tools_4.3.0 parallel_4.3.0 memoise_2.0.1
## [33] dplyr_1.1.2 corpcor_1.6.10 colorspace_2.1-0 Rfast_2.0.7
## [37] RcppZiggurat_0.1.6 vctrs_0.6.3 R6_2.5.1 lifecycle_1.0.3
## [41] stringr_1.5.0 fs_1.6.2 ragg_1.2.5 irlba_2.3.5.1
## [45] pkgconfig_2.0.3 desc_1.4.2 pkgdown_2.0.7 bslib_0.4.2
## [49] pillar_1.9.0 gtable_0.3.3 glue_1.6.2 Rcpp_1.0.11
## [53] whitening_1.4.0 systemfonts_1.0.4 highr_0.10 tidyselect_1.2.0
## [57] xfun_0.39 tibble_3.2.1 knitr_1.43 farver_2.1.1
## [61] htmltools_0.5.5 labeling_0.4.2 rmarkdown_2.22 compiler_4.3.0