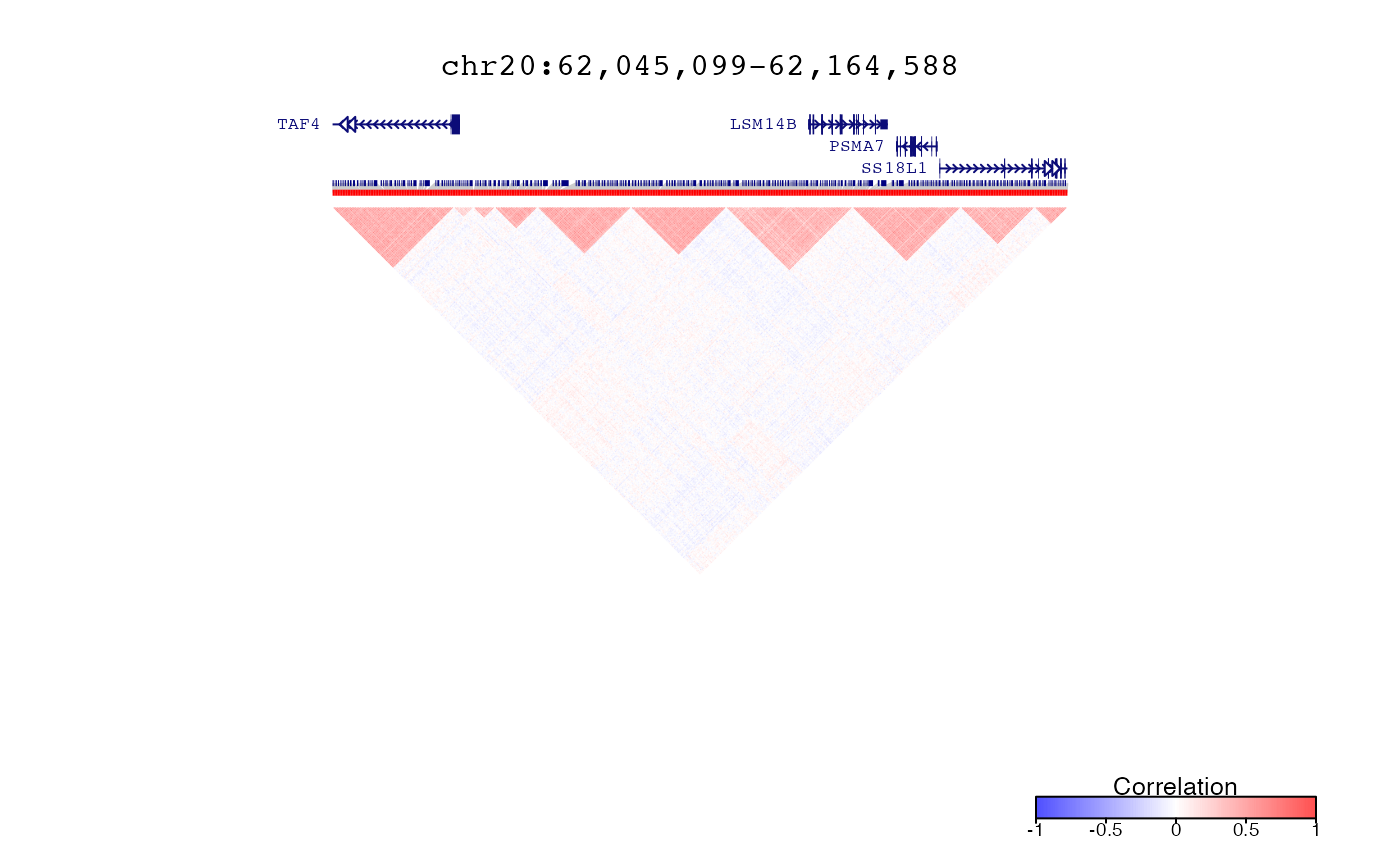
Run hierarchical clustering preserving order
Source:R/local_correlations.R
runOrderedClusteringGenome.RdRun hierarchical clustering preserving sequential order of entries
Arguments
- X
data matrix were *rows* are features in sequential order
- gr
GenomicRanges object with entries corresponding to the *rows* of X
- method
'adjclust': adjacency constrained clustering. 'hclustgeo': incorporate data correlation and distance in bp
- quiet
suppress messages
- alpha
use by 'hclustgeo': mixture parameter weighing correlations (alpha=0) versus chromosome distances (alpha=1)
- adjacentCount
used by 'adjclust': number of adjacent entries to compute correlation against
- setNANtoZero
replace NAN correlation values with a zero
- method.corr
Specify type of correlation: "pearson", "kendall", "spearman"
Details
Use adjacency constrained clustering from adjclust package:
Alia Dehman, Christophe Ambroise and Pierre Neuvial. 2015. Performance of a blockwise approach in variable selection using linkage disequilibrium information. BMC Bioinformatics 16:148 doi.org:10.1186/s12859-015-0556-6
Or, use hclustgeo in ClustGeo package to generate hierarchical clustering that roughly preserves sequential order.
Chavent, et al. 2017. ClustGeo: an R package for hierarchical clustering with spatial constraints. arXiv:1707.03897v2 doi:10.1007/s00180-018-0791-1
Examples
library(GenomicRanges)
library(EnsDb.Hsapiens.v86)
# load data
data('decorateData')
# load gene locations
ensdb = EnsDb.Hsapiens.v86
# Evaluate hierarchical clustering
treeList = runOrderedClusteringGenome( simData, simLocation )
#>
Evaluating:chr20
#>
# Choose cutoffs and return clusters
treeListClusters = createClusters( treeList )
#> Method:capushe
# Plot correlations and clusters in region defined by query
query = range(simLocation)
plotDecorate( ensdb, treeList, treeListClusters, simLocation, query)